This page was last updated March, 2015.
Published

The central 100 pixel by 100 pixel region in this image has been deleted and then inpainted using a diffusion process based probabilistic model of natural images.
Defining probabilistic models using diffusion processes
- Recent work in both nonequilibrium statistical mechanics and sequential Monte Carlo characterizes properties of an intractable distribution in terms of an expectation over a trajectory. This trajectory is typically initialized at a tractable distribution, and terminated at the intractable target distribution. Here we turn this idea on its head, and rather than using a trajectory to evaluate a distribution which has been otherwise defined, we define the target distribution as the endpoint of a diffusion trajectory. This allows the target distribution to be exactly sampled from, easily evaluated, and more easily trained.
- In collaboration with Eric Weiss, Niru Maheswaranathan, and Surya Ganguli.
- See the ICML paper, and the released code.

Dynamics of minimum probability flow learning.
Minimum Probability Flow (MPF) for parameter estimation in intractable probabilistic models
- MPF is a technique for parameter estimation in un-normalized probabilistic models. You can usefully think of it as being similar to Contrastive-Divergence (CD), except that it is a consistent estimator with an associated objective function, rather than only a heuristic for parameter updates. It proves to be an order of magnitude faster than competing techniques for the Ising model, and an effective tool (strictly never slower than CD) for learning parameters for any non-normalizable distribution.
- In collaboration with Peter Battaglino and Michael R. DeWeese.
- See the ICML paper, the PRL paper, and the released code. If you are interested in using MPF in a continuous state space, you should use the method described in the Persistent MPF note.
quasi-Newton minibatch optimization without hyperparameters
- We combine the benefits of stochastic gradient and quasi-Newton optimization methods, by maintaining an online approximation to the Hessian of every single minibatch. This method is kept tractable even for high dimensional problems and large numbers of minibatches by storing the Hessians, and performing all computation, in a shared low dimensional subspace determined by the recent history of gradients and iterates. This leads to faster optimization. More importantly, it saves your sanity from days spent tweaking hyperparameters.
- In collaboration with Ben Poole and Surya Ganguli.
- See the ICML paper, and the released code.

Convergence trace for our technique (black) and competing optimizers.
Characterizing statistical structure in neural spike patterns
- By training Ising, RBM, and sRBM models on patterns of neural activity, we are able to answer questions about: functional connectivity, and how it changes as a result of different interventions; the importance of higher order correlations in the brain; and the entropy of the neural spike code.
- In collaboration with Liberty S. Hamilton, Urs Köster, Alexander G. Huth, Vanessa M. Carels, Karl Deisseroth, Shaowen Bao, Charles M. Gray, and Bruno A. Olshausen.
- See the Neuron paper, the PLOS Computational Biology paper, and Liberty's Github repository.
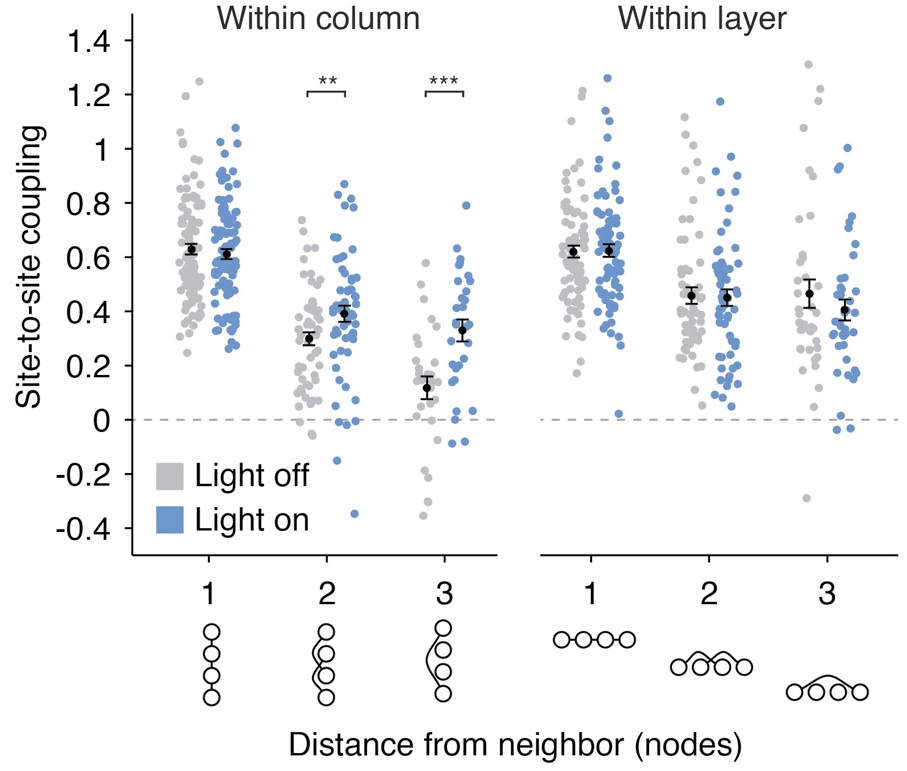
Ising model couplings in the presence and absence of an optogenetic intervention.
A device for human echolocation
- We have built a device which emits bat-like ultrasonic chirps, records the echoes in stereo using artificial pinnae, and then time stretches them so that they are in the human auditory range. By performing minimal signal processing, we present the human brain with a naturalistic and information rich signal which it can rapidly learn to interpret. The hope is that this device will be useful as an assistive device for visually impaired people.
- In collaboration with Nicol Harper, Santani Teng, and Benjamin M. Gaub.
- See the TBME paper and the project website. Also check out the first-person video of its use to the right.
Hamiltonian Monte Carlo (HMC) without detailed balance
- HMC can be viewed in terms of operators acting on a discrete state space. Using this perspective it is possible to derive HMC sampling algorithms which do not rely on detailed balance in order to sample from the correct distribution. Detailed balance causes sampling algorithms to explore the state space by a random walk, meaning they only traverse a distance proportional to the square root of the number of sampling steps. These methods therefore allow much more rapid mixing.
- In collaboration with Mayur Mudigonda and Michael R. DeWeese.
- See the ICML paper, a brief note outlining a closely related scheme, and the released code.

The operators and discrete state space of Hamiltonian Monte Carlo.
Hamiltonian Annealed Importance Sampling (HAIS)
- HAIS is a method for combining Hamiltonian Monte Carlo (HMC) and Annealed Importance Sampling (AIS), so that a single Hamiltonian trajectory can stretch over many AIS intermediate distributions. This allows much more efficient estimation of importance weights - and thus partition functions and log likelihoods - for intractable probabilistic models.
- In collaboration with Jack Culpepper.
- See the tech report, and the released code.

The convergence of estimated log likelihood vs. the number of intermediate AIS distributions.
Lie group models for transformations in natural video
- We develop techniques to make training and inference tractable for high dimensional Lie group models. We use these techniques to learn Lie group models of the inter-frame transformations which occur in natural video, and also in video compression.
- A collaboration with Jimmy Wang and Bruno Olshausen.
- See the core algorithm paper (currently under revision), and also the DCC paper focusing on its use for video compression.

A learned Lie group operator which performs full field rotation.
Bilinear generative models for natural images
- We developed a generative (directed) bilinear model, and applied it to model natural images. A bilinear model form is well matched to many aspects of natural images (e.g., combining surface reflectance and illumination, or factoring apart the overall activity of a group of similar features from the specific feature location or phase within the group).
- A collaboration with Jack Culpepper and Bruno Olshausen.
- See the ICCV paper.

The graphical structure of the directed bilinear model.
Mars Exploration Rover (MER) mission
- Prior to graduate school, I worked on the multispectral camera (PANCAM) team for the MER mission. This involved data analysis of images from the spacecraft, developing super-resolution code for the camera system, and building physical models of Martian dust, so as to remove the effects of dust from Martian spectra.
- See the many papers (including two Science papers) on the Publications page.

A panorama looking back at the lander that carried the Spirit rover to the Martian surface.
Analyzing noise in autoencoders and deep networks
- We explore the effects, both analytically and experimentally, of injecting different types of noise at different locations in an autoencoder. We find that injecting noise improves performance in general, and also that dropout is not the most effective type of noise.
- In collaboration with Ben Poole and Surya Ganguli
- See the NIPS 2013 deep learning workshop paper.

The effect of input and hidden activation noise on learned filters for a denoising autoencoder trained on MNIST.
Other projects with publications (see Publications page for details)
- Optimal and robust storage of patterns in Hopfield networks
- Statistical analysis of MRI and CT breast images
- Connections between the natural gradient and signal whitening
- A fast blocked Gibbs sampler for sparse overcomplete linear models
In progress

An ROC curve showing performance predicting student correctness on new exercises.
Temporal Multi-dimensional Item Response Theory (TMIRT)
- We are building a temporal probabilistic model of the knowledge state of students moving through educational content on Khan Academy.
- In collaboration with Eliana Feasley, Jace Kohlmeier, and Surya Ganguli.

A 2 dimensional slice through function space for a neural network with 2 hidden layers.
Visualizing deep networks in function space
- Although deep networks are remarkably effective at many machine learning problems, we have only limited understanding of the properties of the functions they can compute. I have developed a technique for taking low dimensional slices through the Hilbert space of all possible functions, and I am using these low dimensional slices to both visualize and quantify the ways in which multi-layer networks fill function space.
- In collaboration with Surya Ganguli.